

No mundo dos dados, é essencial encontrar maneiras de deixar os negócios cada vez mais preparados e competitivos para o futuro. Para isso, as empresas recorrem a tecnologias avançadas de armazenamento e processamento de dados. Entre as mais conhecidas, destacam-se o data warehouse e o data lake.
Sumário
Apesar de estarem relacionados, seus sistemas são fundamentalmente diferentes. Entender suas particularidades e diferenças é crucial para orientar estratégias mais eficazes de análise e uso dessas informações. Continue a leitura e descubra para que servem esses armazéns de dados e como eles podem se complementar.
Neste artigo, falaremos sobre os seguintes tópicos:
- O que é um data warehouse;
- O que é um data lake;
- Qual a diferença entre data warehouse e data lake;
- Como é a arquitetura de um data warehouse e um data lake;
- Como cada repositório funciona na prática;
- Quando usar data warehouse e data lake;
- Como data warehouse e data lake funcionam juntos.
O que é um Data Warehouse?
O Data Warehouse (DW) é um repositório projetado para centralizar volumes significativos de dados estruturados, coletados de diversas fontes de uma mesma organização. Seu principal objetivo é garantir uma fonte única e confiável de informações para facilitar consultas e análises frequentes.
A arquitetura de um warehouse é mais complexa do que a de um banco de dados comum e distinta de um data lake, pois ele registra dados históricos que possibilitam a análise de tendências e identificação de padrões que podem influenciar decisões futuras da organização.
A principal vantagem em usar um data warehouse para armazenar dados é potencializar os relatórios, dashboards e ferramentas analíticas que hoje são indispensáveis para diferentes tipos de negócios. Um data warehouse bem estruturado é a chave para o sucesso de ferramentas e equipes de BI.
O que é um Data Lake?
O Data Lake é um repositório onde as informações são mantidas em sua forma bruta e original, incluindo dados estruturados, não estruturados e semiestruturados. Ele é projetado para receber dados de diversas fontes e formatos, sem a necessidade de regras pré-definidas.
Diferente do Data Warehouse, que armazena dados previamente processados e filtrados, o data lake não requer nenhum tipo de tratamento prévio. Ele reúne qualquer tipo de dado, independentemente do tipo e da escala. Os dados do data lake só serão estruturados no momento de visualização.
A flexibilidade é a principal vantagem em usar um data lake para armazenar dados, pois permite uma exploração mais livre dos dados de forma escalável. Com o lake é possível manipular e aplicar uma variedade de técnicas analíticas, como machine learning, análise de big data e dispositivos IoT.
Qual é a diferença entre Data Warehouse e Data Lake?
A diferença prática entre um data warehouse e um data lake é que enquanto um sistema é organizado e estruturado para buscas específicas, o outro é mais flexível, permitindo uma grande diversidade de dados sem a necessidade imediata de organização.
Para entender melhor, imagine que você tem uma grande coleção de livros em casa. Para organizá-los, você decide usar dois espaços diferentes: um é uma biblioteca bem organizada, e o outro é uma grande mesa de estudos.
O data warehouse seria como uma biblioteca, onde cada livro está categorizado por assunto. Os livros de história ficam em uma seção, os de ciências em outra e os de arte em mais uma seção separada. É como se tudo estivesse organizado em prateleiras etiquetadas para você encontrar rapidamente o que precisa.
Agora, o data lake é como uma grande mesa de estudos onde você coloca todos os seus materiais de leitura, como livros, revistas, papéis soltos e rascunhos empilhados. Nesse espaço, não há categorização específica ou organização definida. Você pode colocar qualquer coisa lá, e está tudo junto e empilhado.
Então quando você planeja estudar algo específico, você vai à biblioteca porque lá os livros estão organizados por categorias, e você consegue encontrar rapidamente o que precisa. Por outro lado, quando está em um momento mais exploratório, ou querendo ter acesso a uma ampla variedade de materiais sem se preocupar com a organização, você vai até a mesa, onde tudo está junto, mas sem ordem específica.
Essa é a principal diferença prática entre eles. Enquanto o data warehouse fornece um ambiente estruturado, otimizado e escalável para análise de dados e relatórios, o data lake oferece mais flexibilidade, escalabilidade e capacidade de armazenar diversos tipos de dados em seu formato bruto.
Como cada repositório funciona na prática?
Agora que você sabe as diferenças dos dados a serem armazenados no data warehouse e no data lake, é importante entender como cada tecnologia processa esses dados. Para isso, será necessário entender os conceitos de ETL e ELT.
Imagine que você está organizando um álbum de fotos. No data warehouse com ETL é como se você revelasse diferentes fotos de viagens, amigos e família. Antes mesmo de guardá-las, você as organiza por categoria e as recorta em formato de polaroid, seguindo um padrão pré-definido conforme o estilo do seu álbum.
Agora imagine que os dados são como se fossem as fotos e o warehouse um álbum. Antes de guardá-las no álbum, você revelou, organizou e recortou suas fotos. Dentro do data warehouse acontece algo semelhante, pois os dados são submetidos a um processo de Extração, Transformação e Carga (ETL).
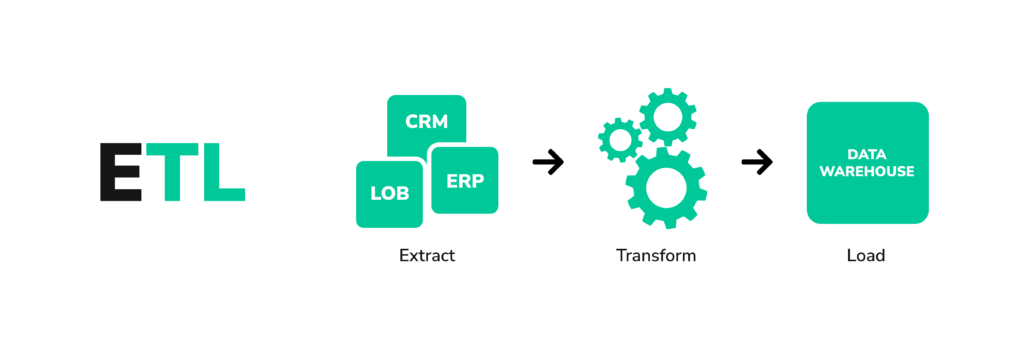
Isso implica na extração dos dados de diferentes fontes, seguida pela limpeza, transformação e formatação para atender a um esquema específico antes de serem carregados no Data Warehouse. Essa manipulação antecipada dos dados visa prepará-los para análises estruturadas e padronizadas.
O processo por ETL torna o data warehouse um ambiente seguro para os profissionais de dados e BI, permitindo acesso aos dados já tratados e organizados para obter informações úteis e estratégicas para apoiar os tomadores de decisões na empresa.
Por outro lado, no Data Lake com ELT, é como se você revelasse e guardasse todas as suas fotos em uma pasta, em sua forma original, sem nenhum critério específico de estilo ou organização. Quando precisar de uma foto para criar um álbum específico, você seleciona as fotos que quiser da pasta e, se necessário, a edita ou organiza de acordo com a necessidade do momento.
No Data Lake com ELT a abordagem é mais flexível. Os dados são armazenados em sua forma bruta, assim como as fotos são guardadas em uma pasta sem organização prévia. O processo de Extração, Carga e Transformação (ELT) implica na extração dos dados de várias fontes e seu carregamento no Data Lake acontece sem muita manipulação inicial.
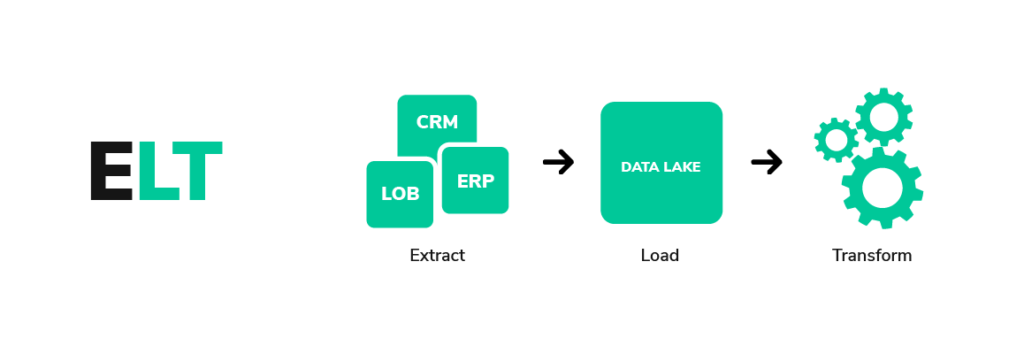
A transformação e preparação dos dados ocorrem quando são acessados para análise. Essa estratégia permite que os dados permaneçam em sua forma original, proporcionando flexibilidade para serem adaptados e transformados de acordo com as necessidades específicas no momento da análise.
O processo por ETL torna o data lake um ambiente com mais flexibilidade e possibilidade de acessar os dados em sua forma original. Em termos de custos, um data lake geralmente tem um melhor custo-benefício que um data warehouse por operar em uma escala de petabytes.
Quando usar um Data Warehouse e um Data Lake?
Agora que você já sabe o que é um data warehouse e um data lake, além das principais diferenças entre eles, veja uma comparação de suas principais características e alguns exemplos de casos de uso.
| Características | Data Warehouse | Data Lake |
| Tipo de dado | Estruturado | Estruturado, não estruturado ou semiestruturado |
| Esquema | On-write (predefinido) | On-read (na hora da análise) |
| Fontes | Internas e externas, mas principalmente fontes internas | Diversas fontes, incluindo internas e externas, IoT, redes sociais, entre outras |
| Escalabilidade | Menos flexível, escalabilidade limitada | Altamente escalável, pode lidar com grandes volumes de dados de forma mais flexível |
| Usuários | Analistas de negócios e profissionais de BI que usam SQL | Cientistas de dados, desenvolvedores de dados que usam Python, por exemplo, e analistas de negócios que usam SQL com os dados curados |
| Custo de armazenamento | Custo mais alto – escala de terabytes | Custo reduzido – escala de petabytes |
| Casos de uso | Relatórios padronizados e análises estruturadas e correlacionadas. Exemplos: consultar o total de vendas por região nos últimos seis meses, comparar a margem de lucro entre diferentes categorias de produtos no último ano, identificar o padrão de compra dos melhores clientes nos últimos três anos, etc. | Análises avançadas, big data, machine learning, exploração de dados não estruturados. Exemplos: consultar as vendas de um determinado produto em um determinado dia, analisar sentimentos dos clientes sobre determinado produto conforme seu engajamento nas mídias digitais, etc. |
Em resumo, os data warehouses são mais adequados para cenários que exigem:
- Dados estruturados e consistentes: ao lidar com dados estruturados de diversas fontes, um data warehouse garante consistência e confiabilidade dos dados.
- Inteligência empresarial: os data warehouses são otimizados para fins de relatórios, análises e inteligência de negócios, fornecendo uma visão consolidada dos dados.
- Desempenho da consulta: se a sua organização exigir tempos de resposta de consulta rápidos para análise de dados em grande escala, a estrutura e a indexação otimizadas de um data warehouse proporcionam desempenho de consulta eficiente.
Já os data lakes são adequados para cenários que exigem:
- Análise exploratória: os data lakes permitem que os usuários armazenem e analisem dados brutos sem esquemas predefinidos, tornando-os ideais para análise exploratória e descoberta de dados.
- Variedade de dados: ao lidar com diversos tipos de dados, como feeds de mídias sociais, arquivos de log ou dados de sensores, os data lakes fornecem uma solução de armazenamento flexível.
- Escalabilidade: se a sua organização lida com grandes volumes de dados que precisam ser armazenados de maneira econômica, um data lake pode acomodar esse requisito de escalabilidade.
Como o Data Warehouse e o Data Lake funcionam juntos?
A escolha entre um data warehouse e um data lake não precisa ser exclusiva. Na verdade, eles podem trabalhar juntos de forma complementar. Em muitos casos, as organizações descobrem que uma combinação de data lake e data warehouse é a abordagem mais poderosa para atingir seus objetivos.
Este modelo híbrido permite a flexibilidade e a escalabilidade de um data lake, ao mesmo tempo que aproveita os recursos de consulta estruturados e otimizados de um data warehouse. Ao integrar os dois, a empresa pode ingerir dados brutos no data lake para realizar análises exploratórias e, em seguida, transformar e carregar dados relevantes em um data warehouse para relatórios e análises adicionais.Compreender as diferenças entre data lake e data warehouse é vital para projetar uma estratégia de dados mais eficaz. Ao considerar fatores como estrutura de dados, fontes, escalabilidade, custos, requisitos do usuário e casos de uso, as organizações podem tomar decisões informadas sobre o repositório mais adequado para suas necessidades de dados.
Conclusão
Em conclusão, a escolha entre data warehouse e data lake depende das necessidades específicas de dados de cada organização. Os data warehouses são ideais para cenários que exigem dados estruturados e consistentes, inteligência empresarial e desempenho eficiente de consultas. Eles são otimizados para fornecer uma visão consolidada dos dados e suportar relatórios e análises detalhadas. Por outro lado, os data lakes são mais adequados para análises exploratórias, manipulação de diversos tipos de dados e situações que requerem alta escalabilidade e flexibilidade. Eles permitem o armazenamento econômico de grandes volumes de dados brutos, facilitando a exploração e descoberta de novas informações.
Entretanto, muitas organizações encontram benefícios significativos na integração de ambos os sistemas. O modelo híbrido combina a flexibilidade e escalabilidade de um data lake com os recursos de consulta estruturada de um data warehouse. Isso permite a ingestão de dados brutos para análises exploratórias no data lake, seguido da transformação e carregamento de dados relevantes no data warehouse para análises e relatórios mais detalhados.


")



